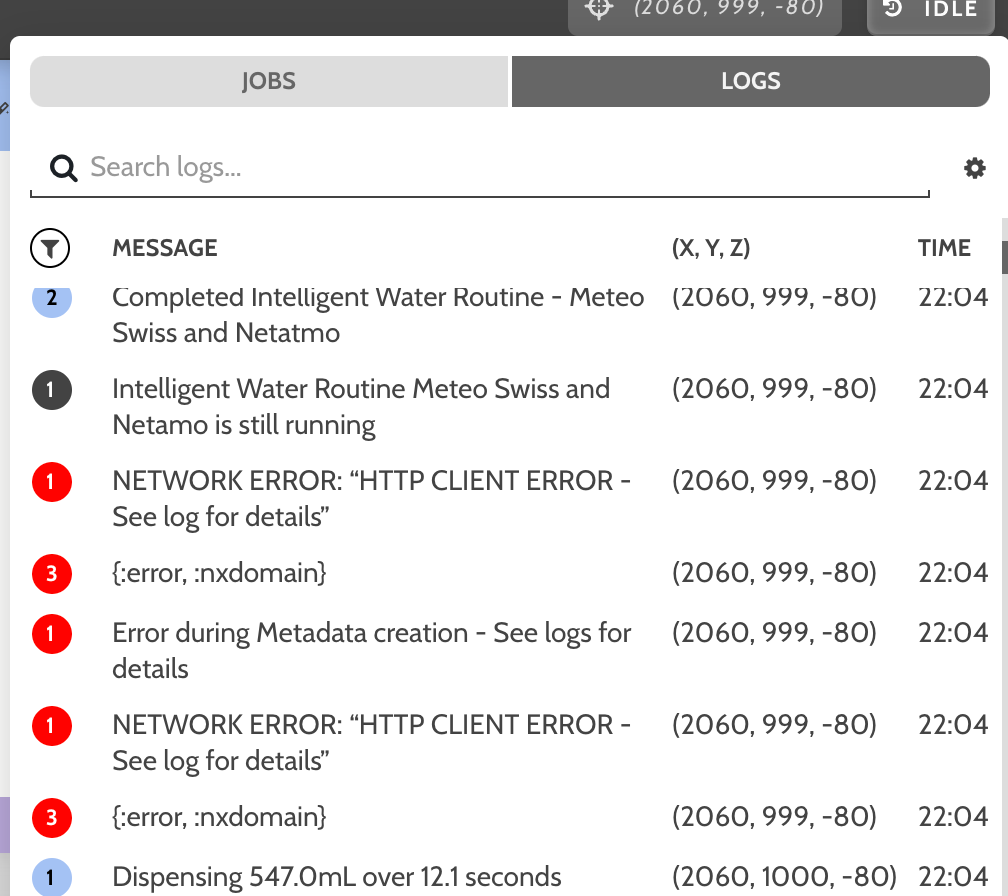
My sequences sometimes fail due to DNS problems. Seeing errors like these in the logs: {:error, :nxdomain}
The root cause is probably my unstable Wifi network since my Farmbot is behind a repeater this might be not ideal…
Anyway, I’m thinking of many users may could have similar issues, since DNS queries are made with UDP. Lost packets will never be returned to the Farmbot.
Another thing would be to enable some sort of DNS caching… But this could be not ideal for DNS Loadbalancing…
By the way: Is it possible to do a packet capture on the raspberry it self?
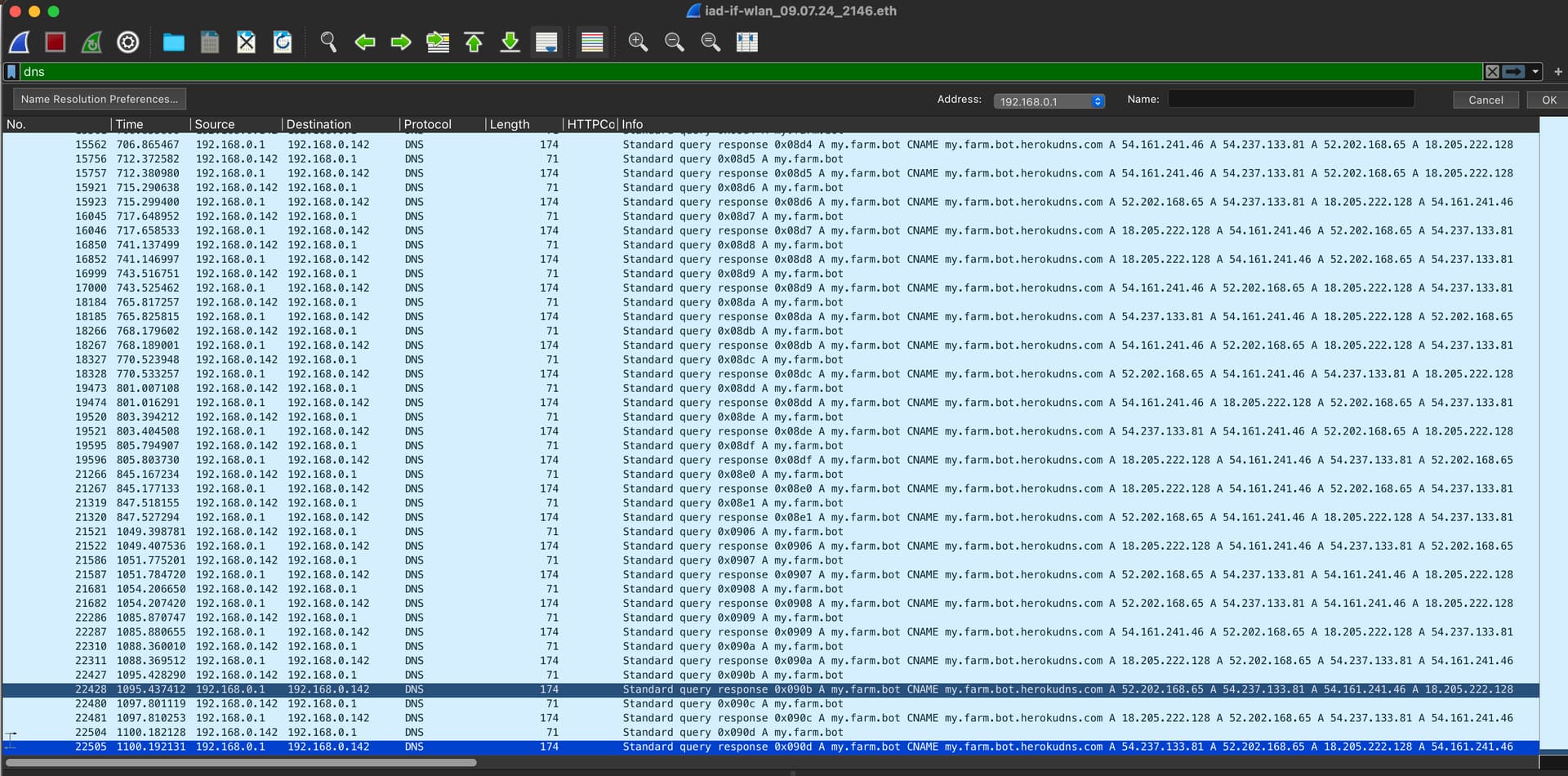
Today I made a trace on my router, and I saw (I’m using plant group location based sequences), on each iteration a new DNS query is made. The router replied to all of them, but shortly before I stopped the trace, I got the “nxdomain” error. It must have been some sort of fatal error since the whole sequence stopped in the first quarter of processing 70 plants.
Does that Wireshark screen shot capture those FBOS errors at 22:04 ?
I’m not convinced that your router DNS is to blame for these :nxdomain errors (?)
It seems to reliably return DNS query responses in under 10ms.
Are you thinking that some UDP response packets are not arriving over the Wi-Fi connection to FBOS ?
Potentially, yes. You will need to add tcpdump to the FBOS Linux build (Buildroot Linux forum should have the ‘how to’ details), then make your custom farmbot_system_rpi3-portable-1.23.1-farmbot.1 package and use that in your FBOS build.
It should also be possible (if you can get a compatible tcpdump executable + required SO libraries) to sftp those to /tmp and run them from there. This requires you to have a custom FBOS build which include ssh support (not hard).
You might need to balance the effort of setting up DNS over TCP/HTTPS versus running a wired Ethernet connect to the bot. (Easy to do with Ethernet over Powerline devices)
Edit: @farmS1m the FBOS low-level DNS code uses Erlang OTP modules. You can examine their code to see what timers might be used before that :nxdomain failure is asserted.
Edit: @farmS1m I looked in the FBOS code but did not find “Error during Metadata creation - See logs [ . . . ]” ?
Yes the trace has been started at 21:46, and run for 19 minutes. I stopped the trace shortly after the issue occured.
Yes thats what I’m thinking of. Therefore I might will either try to setup a rpi image with tcpdump, or will consider to use a Powerline
Thats correct it is a custom log message from my code:
plant = variable("Plant")
plant_id = plant.id
plant_url = "/api/points/" .. plant_id
watered_last_amount = tonumber(env("watered_last_amount"))
-- toast(plant_id)
-- toast(plant_url)
result = api({
method = "put",
url = plant_url,
body = {
meta = {
watered_last = local_time("date"),
watered_last_timestamp = tostring(os.time()),
watered_last_amount = watered_last_amount
}
}
})
if result then
-- toast("Metadata creation ok", "debug")
else
send_message("error", "Error during Metadata creation - See logs for details", "email")
end
api_result = api({method = "GET", url = plant_url})
result = json.encode(api_result)
-- send_message("info", result)
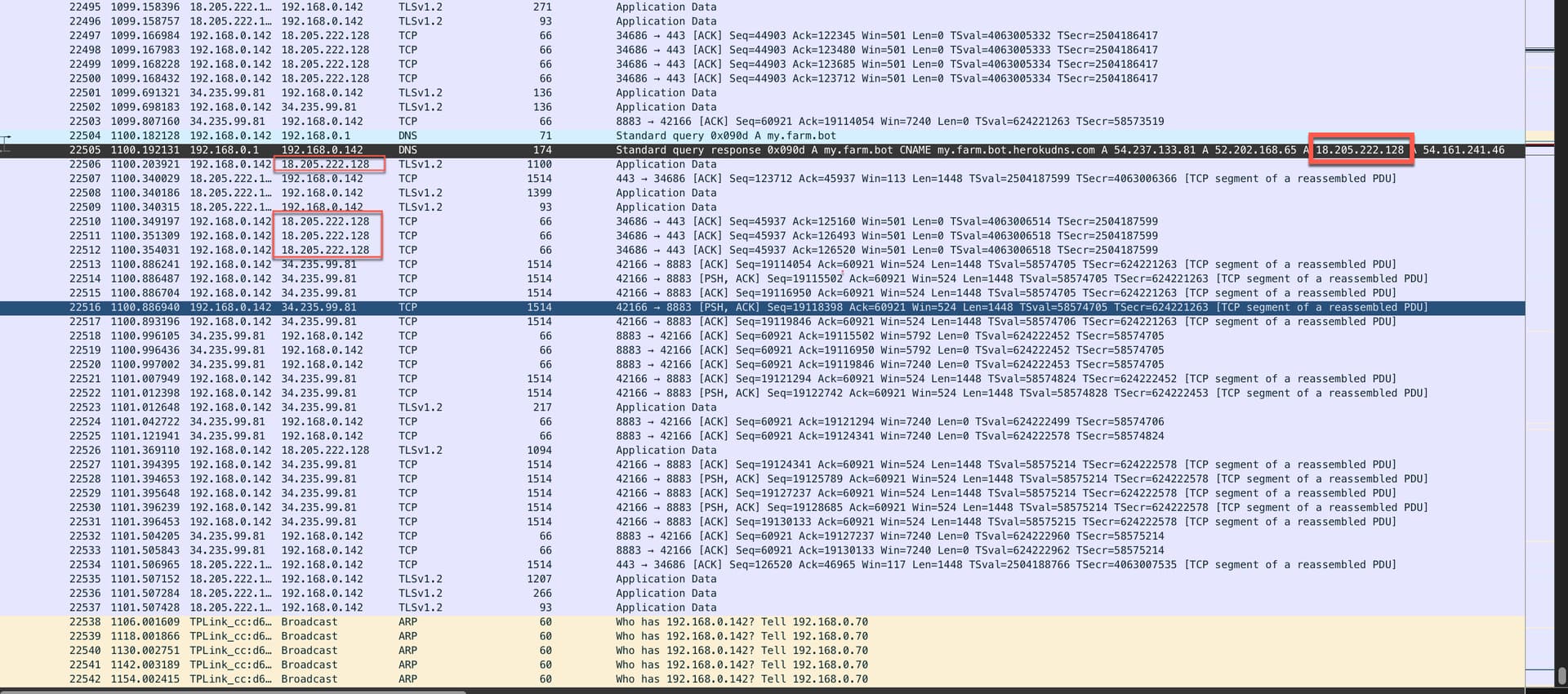
From the trace it is hard to say at least it looks like the FB did a request after the last DNS query seen in the trace. Probably the next dns query done from FB is not included in the trace, as It never got transported to the router. I don’t know.
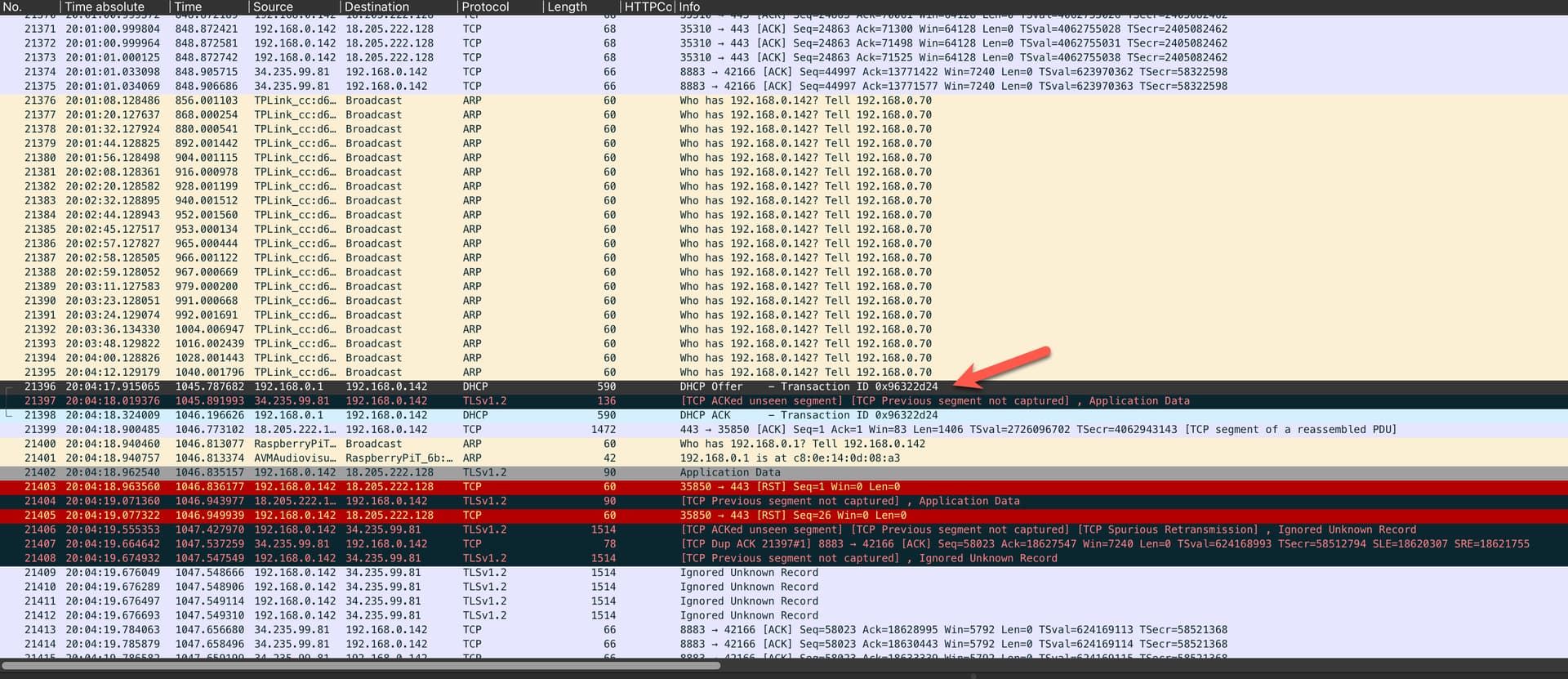
Getting one step closer. The setting to display absolute timestamps in Wireshark has helped a lot! I was able to pin it to 22:04 (UTC 20:04).
It looks like the FB received a new DHCP offer at that time. Probably because the Wi-Fi Adapter lost its signal and recovered from it a few minutes later. Unfortunately my trace was made with a host filter (of the FB IP), therefore I do not see the DHCP request from the FB with origin IP 0.0.0.0.
I think this is proof enough, my Wi-Fi is still (Even I already have installed a repeater, the signal strength fluctuates between 36 - 84%! This is quite bad, but think the shutter blinds have some impact or some neighbors Another thing could be some random channel auto reconfiguration. Will might check some repeater / router logs according to this.
@jsimmonds Do you know if a total loss of the Wi-Fi signal would be logged somewhere?
Don’t know but will dig around . . wpa_supplicant on the FBOS Linux is managed by Elixir app :vintage_net_wifi and relations. There should be logging that we could see or enable.
Just thinking bigger-picture about the :nxdomain abort from HTTP Client here
Should DNS client query requests normally be re-tried n-times on response timeout ?
Are there other signs in latest Wireshark capture that indicate a loss of internet apart from 18.205.222.128 unexpectedly REJecting ?
What I’m wondering is whether AWS load-balancing is working correctly ?
Edit: My mistake there: If NO Internet then AWScannotREJect
Edit: Ooops; TCP Header has no REJ flag, only RST
At the moment (at least today) I was not able to reproduce the issue. But I expect it to be back in a few days and will do a new trace.
The strange thing is I didn’t had the :nxdomain in the wireshark trace. So I’m also asking myself who responds with :nxdomain…
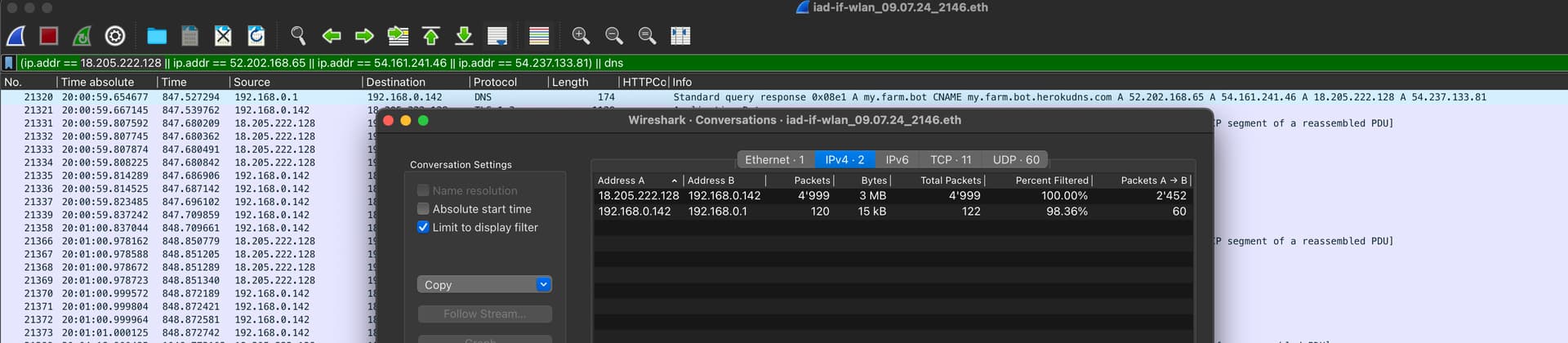
I think in general it looks good. For some reason all the connection went all the time to 18.205.222.128, asking myself if the DNS roundrobin even works…
That :nxdomain error is likely coming from the :hackney HTTP client package and you will never see that “on the wire”
Your Wi-Fi is stable enough.
I’m following several conversations between FBOS and 18.205.222.128 trying to understand how they end. (:hackney uses a pool of HTTPS clients) TCP Keepalive seems to be enabled at the AWS end.