I’m “calibrating” the FBOS v9.2.1 Farm Event “capacity” limit 
When FarmEvents total > 9000 the Erlang VM stops and crashes.
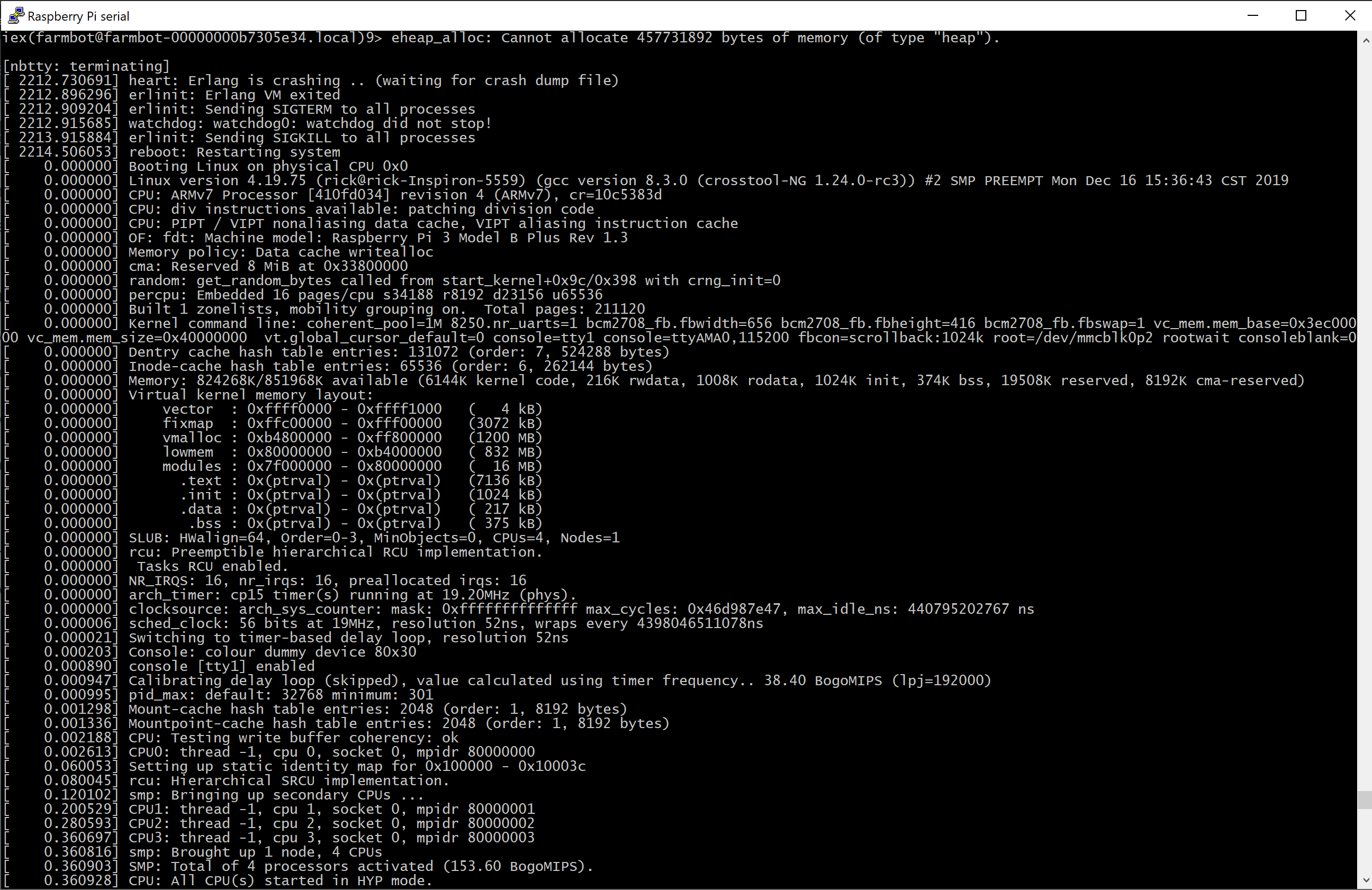
The console output and the /etc/erlinit.config suggest that I should find a dump file at /root/crash.dump but I never do !
Here’s the FBOS console showing the crash
[edit 0]
I think the Erlang doc tells me why
Need to add ERL_CRASH_DUMP_SECONDS=-1 to /etc/erlinit.config for env.
For now, I’ll do this on my private FBOS build and will not raise any issue or feature_request
Just curious ( @RickCarlino ) what the expected max for total Farm Events is spec’ed at ?

[edit 1]
Slowly realized that the change has to happen in farmbot_system_rpi3/blob/master/rootfs_overlay/etc/erlinit.config

[edit 2]
@RickCarlino any chance you could add that env item to the next release of farmbot_system_rpi3 ? 
@jsimmonds
I’m “calibrating” the FBOS v9.2.1 Farm Event “capacity” limit
By “calibrate” I am assuming you were just running a theoretical benchmark, correct? Or are you trying to accomplish a real-world use case? Can you tell me more about the FarmEvent you were trying to use? Was it that you created 9,000 FarmEvents in the database ( ), or you created a FarmEvent that had 9,000 points of execution? I like to evaluate bugs on a severity:likelihood scale, and although this is high in severity, it seems low in likelihood. If I am understanding the issue correctly, it might be better to set limits on this resource, which currently has few unlike logs or points.
), or you created a FarmEvent that had 9,000 points of execution? I like to evaluate bugs on a severity:likelihood scale, and although this is high in severity, it seems low in likelihood. If I am understanding the issue correctly, it might be better to set limits on this resource, which currently has few unlike logs or points.
The long-term “forever” solution to this is to re-write the FarmEvent data structures to use lazy evaluation. Right now, the system is already pretty strained with relation to event scheduling, to the point that some parts of the FarmEvent handlers had to be written in C (never a good sign). It’s been a while since I’ve had to look at that part of the codebase, though and I may need to re-visit to refresh my memory.
I’d be more in favor of setting a limit elsewhere in the stack rather than putting more fuel on the fire for performance issues, especially now that RPi0 devices are deployed. We’ve done similar things for points and logs.
Main concerns:
- Express devices are very resource constrained and might be adversely affected by having that many points. We could change the limit for
rpi3 only, but it would be nice to maintain parity between models as much as possible.
- The frontend as it is currently designed probably can’t handle that many events. How did the web app perform under these conditions?
If you really need this feature I can take a deeper look. I think I might not be understanding the situation entirely.
expected max for total Farm Events is spec’ed at ?
Usually we wait for events like this to happen before we set hard limits, although you may have shown there is a need. Some of the limits were set here: https://software.farm.bot/v9/docs/account-limitations
@RickCarlino
Thanks for your expansive and considered response.
Correct. Initially 2 different short Sequences, each repeating every 5 minutes across a 16 day interval.
Didn’t miss a beat or raise a sweat and tallied the entire interleaved sequences correctly.
In reality I’m trying not to report a bug as such  but only to report that the Erlang VM crash dump ( that I want to examine ) is not getting written. That’s likely due to the BEAM env missing that
but only to report that the Erlang VM crash dump ( that I want to examine ) is not getting written. That’s likely due to the BEAM env missing that ERL_CRASH_DUMP_SECONDS=-1 item.
I appreciate that you probably don’t want the little RPi0 recording dumps, but the RPi3B+ wouldn’t be fussed.
Yes, I noticed Scheduler usage sitting around 14% for many many minutes ( most time spent in various Calendar.ISO functions ).
It seems likely that the FarmbotCeleryScript.Scheduler process is the one that blows its :total_heap_size.
F.y.i., that’s a 404 link, but I did find Account limitations here 
For now, please don’t worry too much about this topic !
I’ll report back after I’m able to get a crash.dump file that I can analyze.
Ah, sorry for any confusion @jsimmonds! As always, we appreciate your help in debugging. I will put the ERL_CRASH_DUMP_SECONDS=-1 on my TODO list for the next time that I need to update the Nerves system.
Thanks @RickCarlino . . that’s cool.
Meantime, I’ll make a custom Rpi3 system build and verify that this change is all we need.
1 Like
@RickCarlino, I cloned farmbot_system_rpi3 and added ERL_CRASH_DUMP_SECONDS=-1 to rootfs_overlay/etc/erlinit.config then built the package . . and presto !
I can now generate a crash dump file.
Simply confirming that’s all we need to change.
( The Erlang doco sure is impressively detailed and accurate )
Great to hear @jsimmonds. I have put this on my backlog. PS: Sorry for the radio silence over the past week 
No sorries . . My Congratulations on the recent releases’ Big milestone features 
@jsimmonds This will be enabled in FBOS v10.1.0, which depends on farmbot_systme_rpi3 v1.11.4-farmbot.0. It is currently building on my machine and will be published shortly. Thanks again for the help.
Lovely  Thank You !
Thank You !
We also get a shiny newer Kernel, with Elixir 1.10.3 and lots of other updates and fixes included.