Hello everyone,
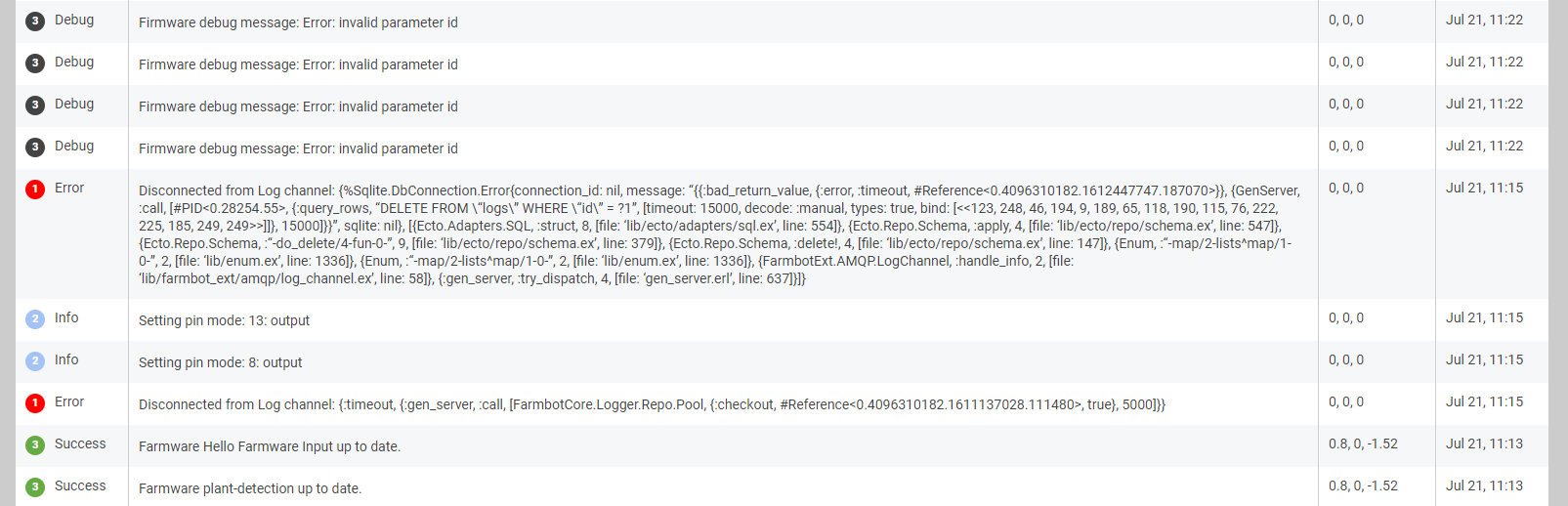
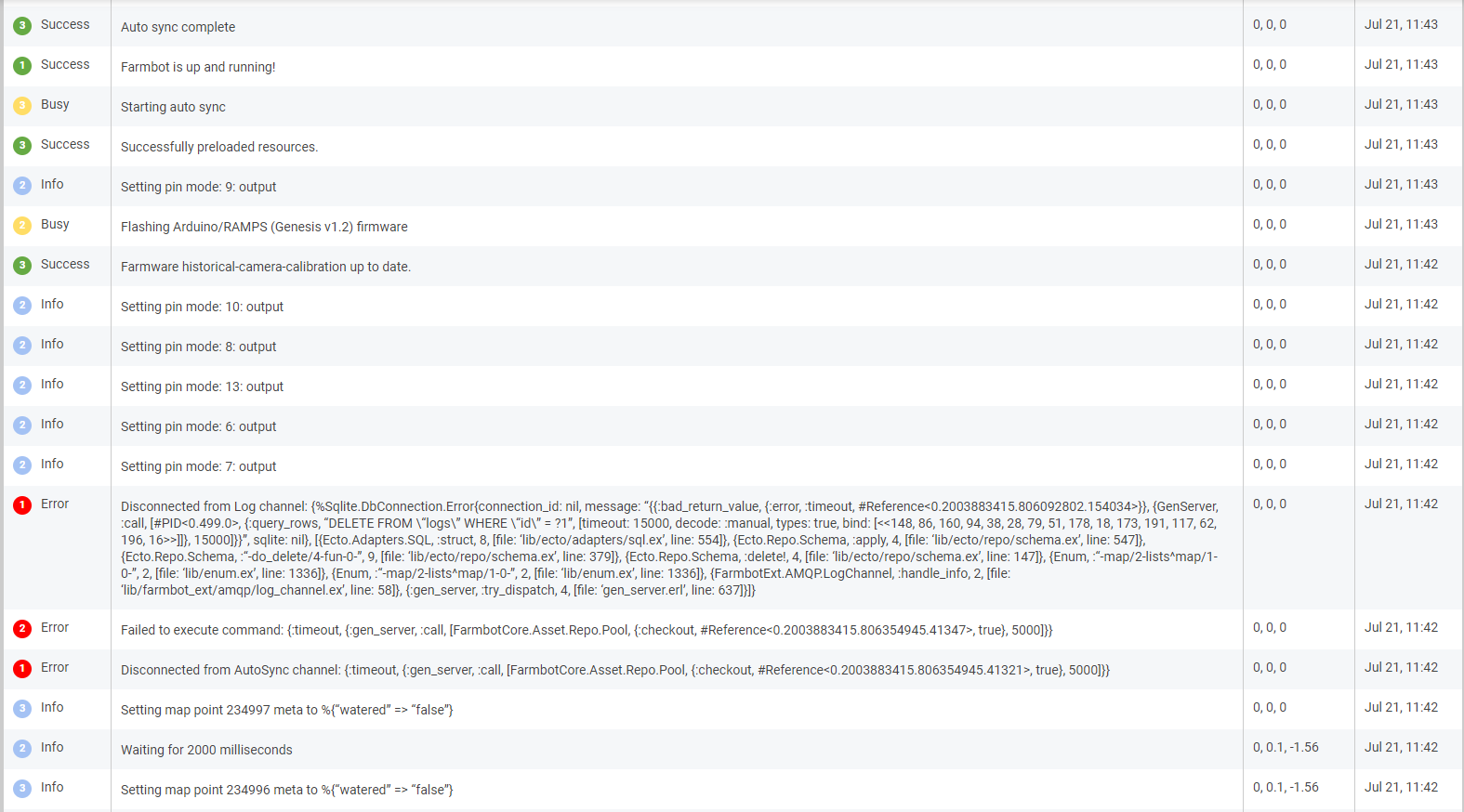
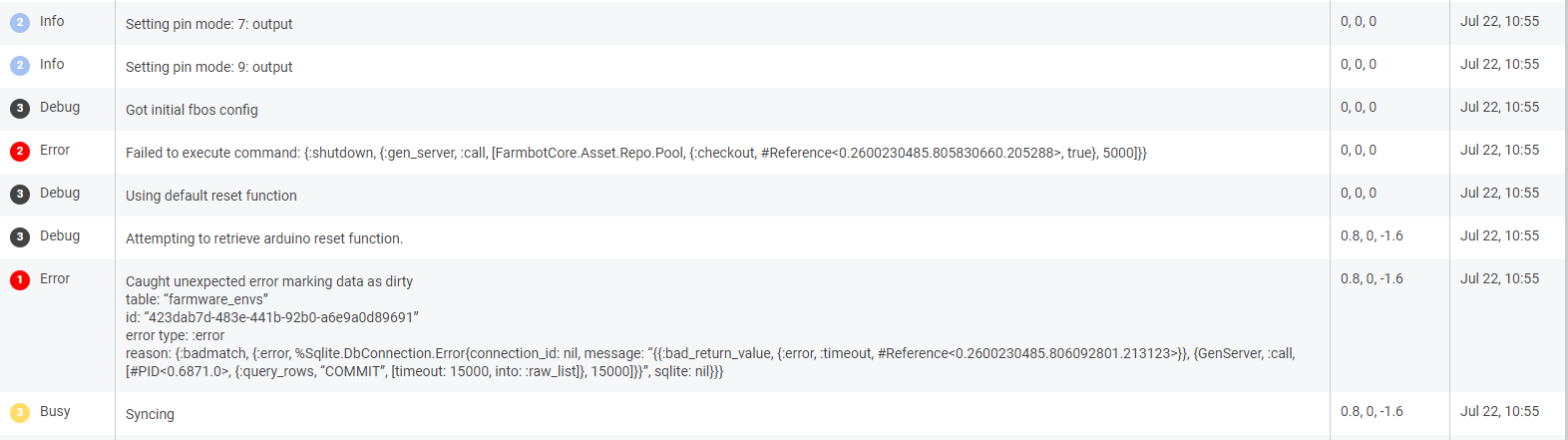
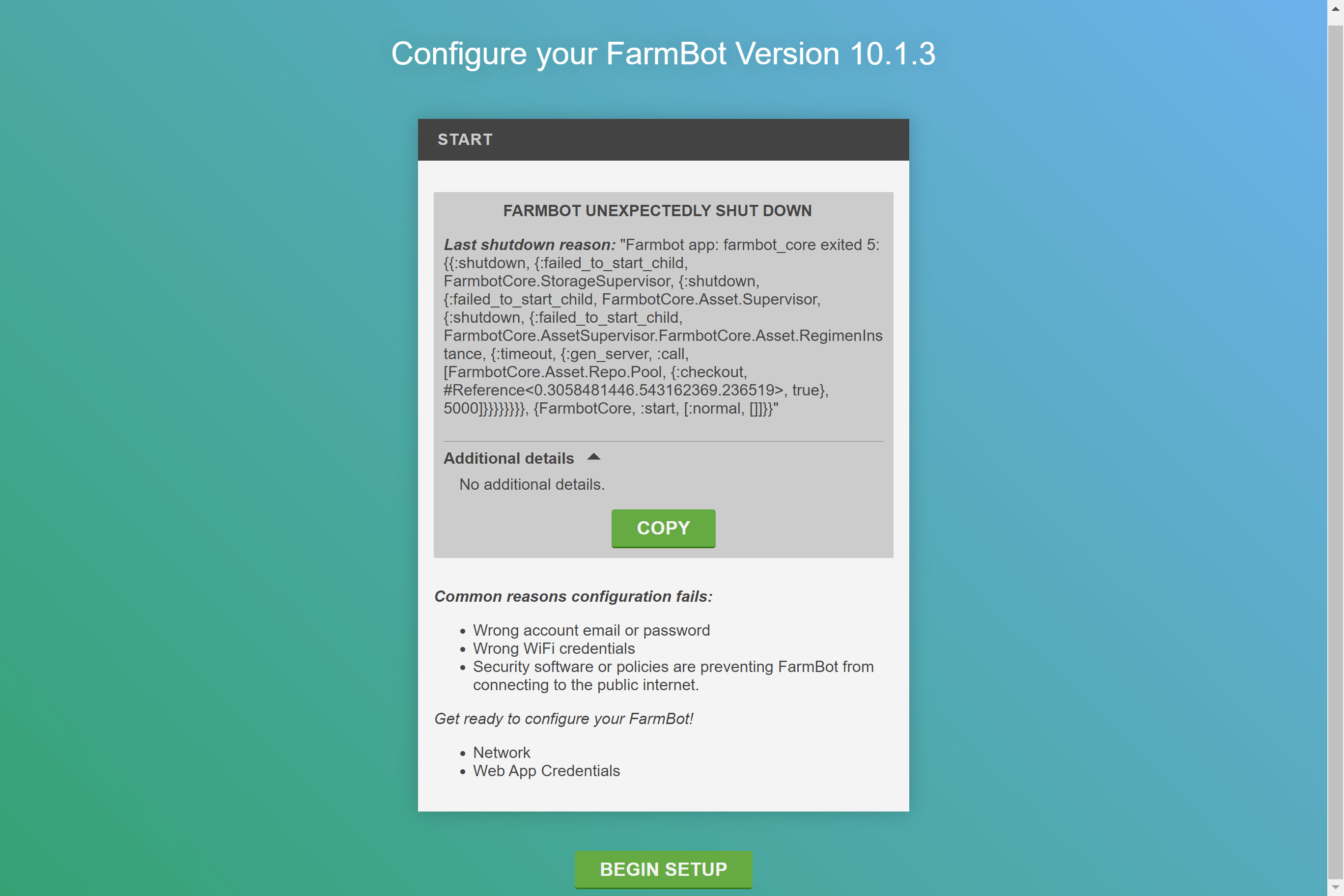
did anyone else see similar errors coming up recently? This one comes up a few times each day, but I wasn’t able to find out what causes this. Maybe something went wrong with my account @RickCarlino ?
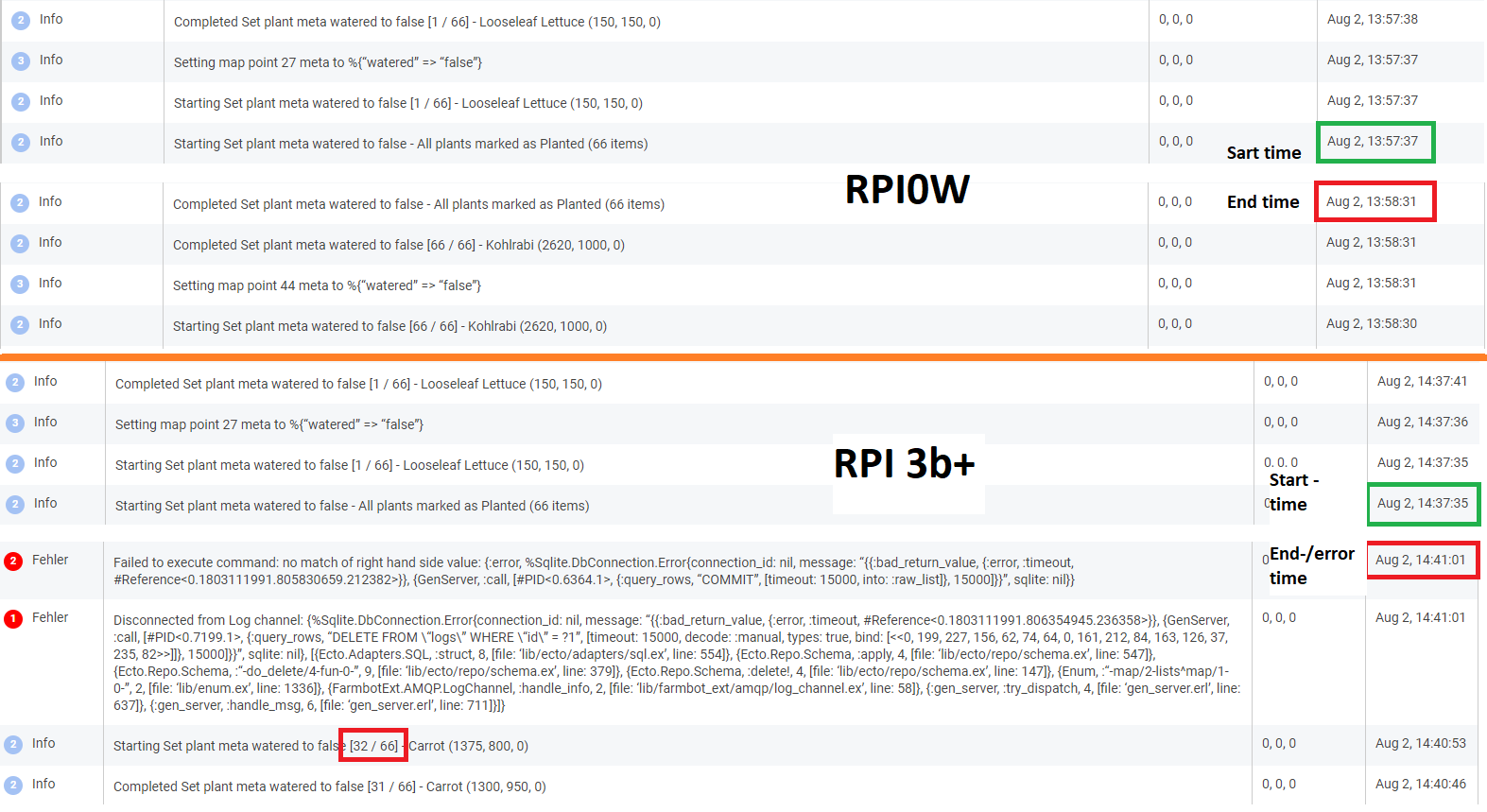
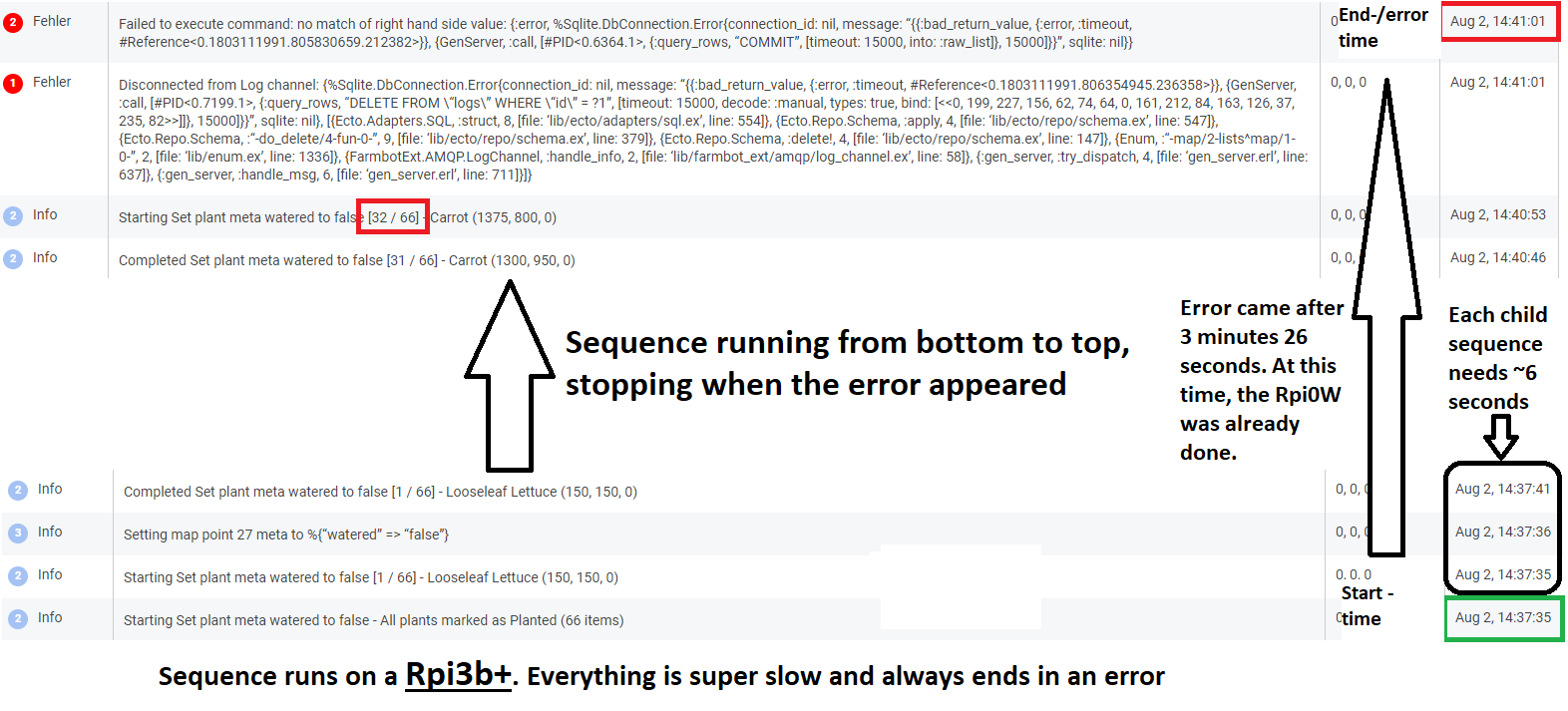
Disconnected from Log channel: {%Sqlite.DbConnection.Error{connection_id: nil, message: “{{:bad_return_value, {:error, :timeout, #Reference<0.4096310182.1612447747.187070>}}, {GenServer, :call, [#PID<0.28254.55>, {:query_rows, “DELETE FROM \“logs\” WHERE \“id\” = ?1”, [timeout: 15000, decode: :manual, types: true, bind: [<<123, 248, 46, 194, 9, 189, 65, 118, 190, 115, 76, 222, 225, 185, 249, 249>>]]}, 15000]}}”, sqlite: nil}, [{Ecto.Adapters.SQL, :struct, 8, [file: ‘lib/ecto/adapters/sql.ex’, line: 554]}, {Ecto.Repo.Schema, :apply, 4, [file: ‘lib/ecto/repo/schema.ex’, line: 547]}, {Ecto.Repo.Schema, :“-do_delete/4-fun-0-”, 9, [file: ‘lib/ecto/repo/schema.ex’, line: 379]}, {Ecto.Repo.Schema, :delete!, 4, [file: ‘lib/ecto/repo/schema.ex’, line: 147]}, {Enum, :“-map/2-lists^map/1-0-”, 2, [file: ‘lib/enum.ex’, line: 1336]}, {Enum, :“-map/2-lists^map/1-0-”, 2, [file: ‘lib/enum.ex’, line: 1336]}, {FarmbotExt.AMQP.LogChannel, :handle_info, 2, [file: ‘lib/farmbot_ext/amqp/log_channel.ex’, line: 58]}, {:gen_server, :try_dispatch, 4, [file: ‘gen_server.erl’, line: 637]}]}